Hace unos días leía en Twitter una frase que decía, más o menos, lo siguiente: » Lo bueno de ser mayor de 40 años es que la mayoría de las tonterías que hice en mi vida fueron antes de la aparición del Internet». La frase me causo gracia y, al mismo tiempo, una sensación de tranquilidad pues, felizmente, no existen pruebas de las tonterías que todos los mayores de 40 hicimos durante nuestra adolescencia. Sin embargo, me quedo dando vueltas en la cabeza la pregunta ¿A qué se enfrentan los adolescentes de ahora cuyas actividades cotidianas son registradas vehementemente en incontables redes sociales por ellos o sus amigos? Revisando el informe de Ipsos Perú sobre el Perfil de los usuarios de redes sociales 2012 pude constatar que el 39% de los menores entre 8 y 11 años tienen una cuenta en redes sociales mientras que en el segmento de menores entre 12 y 17 esta cifra se dispara a un importante 84%. El mismo informe nos indica que más del 80% de los usuarios de redes sociales en el Perú ha subido fotos alguna vez mientras que el 50% de ellos ha creado álbumes de fotos y acostumbra etiquetar fotos (personales o de terceros). Sigue leyendo
Hay 26 puestos etiquetados Facebook (esta es la página 1 de 3).
La naturaleza de la competencia en la era digital
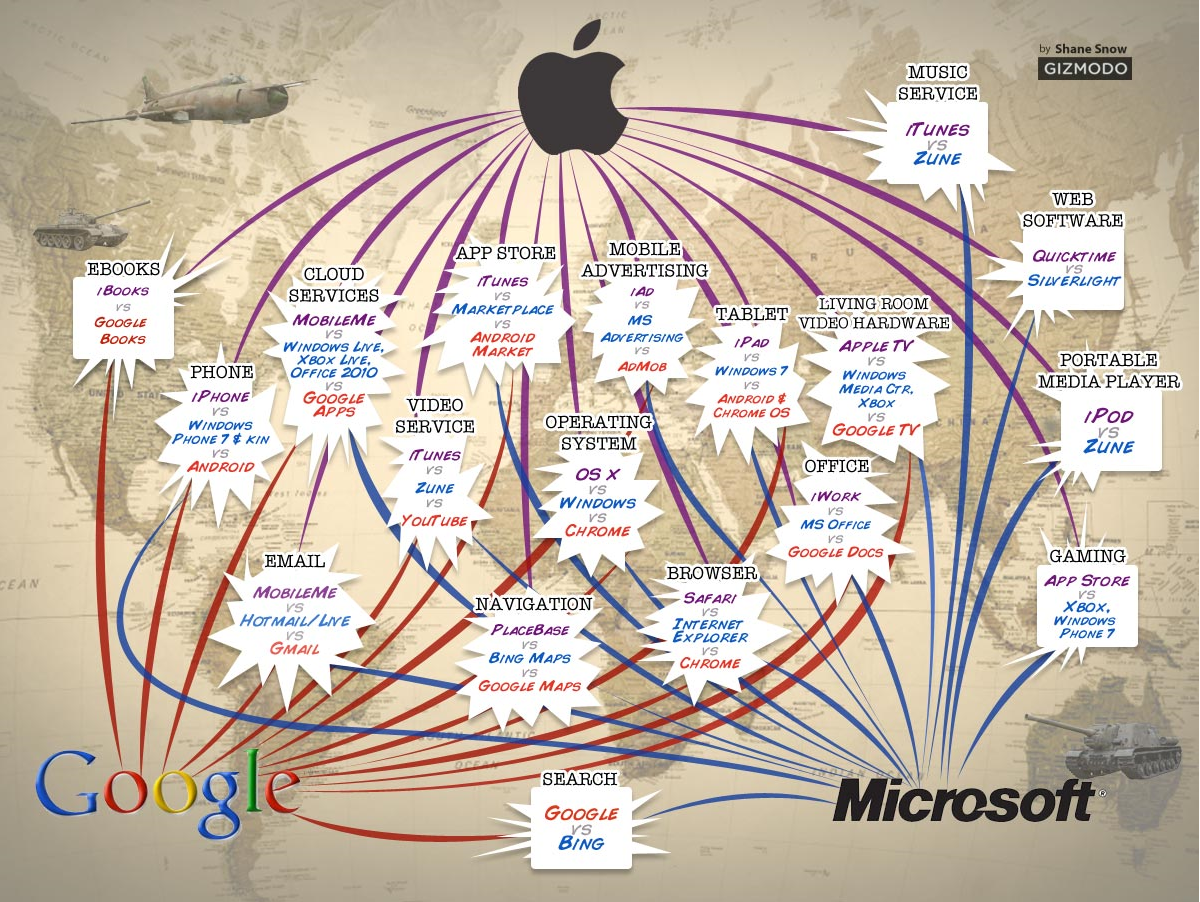
Luego de algunos meses de gran pereza y de poca actividad, logré terminar de leer un pequeño paper de Justus Haucap y Ulrich Heimeshoff publicado por el Instituto de Competencia Económica de Düsseldorf bajo el rótulo de «Google, Facebook, Amazon, eBay: Is the Internet Driving Competition or Market Monopolization?» (Google, Facebook, Amazon y eBay: ¿La competencia por impulsar Internet o la monopolización del mercado»). Haucap y Heimeshoff nos ofrecen una más que recomendable lectura sobre el panorama actual de varias industrias en línea a través de un repaso a literatura económica más relevante, respecto de como opera la libre competencia en los mercados tecnológicos.
No hay que ser muy avispados notar que muchas de las empresas de éxito en Internet son en realidad monopolios. Google, Youtube, Facebook y Skype son ejemplos típicos de empresas que dominan sus mercados de referencia por goleada. La cuestión fundamental desde una perspectiva de política de competencia no debe ser si estas empresas tienen una posición dominante hoy, sino por qué tienen una cuota de mercado tan alta y si nos encontramos ante un fenómeno temporal.
Activismo Digital en el Perú
Cuando el 25 de enero de 2011, quince mil manifestantes ocuparon la Plaza Tahrir en Egipto el mundo fue testigo no solo de una impresionante protesta sino también de la primera manifestación de activismo digital. En efecto, en esa oportunidad los egipcios utilizaron la potencia y el alcance de redes sociales como Facebook y Twitter para encender y acelerar su movimiento y terminar con el derrocamiento del régimen que gobernaba Egipto hacía más de 30 años. Así como antiguamente en las revoluciones se usaba la comunicación boca a boca, o como en el caso de Lutero los panfletos impresos ayudaron a diseminar su mensaje, en estos últimos años venimos siendo testigos del uso de las redes sociales como herramienta para diseminar mensajes políticos y el Perú no es ajeno a esto.
En las últimas semanas y meses, hemos sido testigos de muchas discusiones políticas en Twitter en relación con proyectos de ley, decisiones políticas, elecciones, revocatorias u opiniones de políticos vertidas en redes sociales como el hashtag (#presidentenosepique) de este fin de semana iniciado por el mismísimo expresidente Alan García. Como nuestro blog no es de corte político queremos comentar el tema del activismo digital como expresión de la sociedad y, finalmente, un derecho humano tal como expresamos en un post anterior sin entrar a la discusión acerca de las opciones políticas detrás de los reclamos ciudadanos.
El mercado de valores y las redes sociales
El mercado de valores es aquel mecanismo que permite a los inversionistas realizar operaciones sobre valores de renta fija o variable de tal forma que aquellos con excedentes de capital encuentren a los que requieren de flujos dinerarios que les permitan solventar sus negocios. En este artículo, comentaremos la reciente regulación del mercado de valores norteamericano que permite notificar hechos relevantes mediante del uso de redes sociales.
Para lograr que la determinación de precios en este mercado sea adecuada y responda a la ley de oferta y demanda resulta indispensable que todos los inversores tengan acceso a la misma información (al mismo tiempo y en la misma calidad) y que los emisores compartan su información relevante de un modo veraz, suficiente y oportuno. Esta obligación busca eliminar los beneficios económicos que la asimetría de información podría generar en el mercado.
Para ello se exige que los emisores de valores pongan en conocimiento del mercado cualquier información relevante que pudiera afectar la decisión de invertir o no en un determinado valor en particular evitando que cualquiera se pueda beneficiar de algún dato desconocido para los demás. Por esta razón, las entidades reguladoras del mercado de valores del mundo establecen una serie de obligaciones que deben cumplirse -bajo amenaza de sanción- para lograr este equilibrio en el acceso a información.
En Julio del año pasado el CEO de Netflix, Reed Hastings, publicó en su cuenta de Facebook personal que, por primera vez en la historia de la empresa, sus usuarios habían consumido más de mil millones de horas en un mes. Este post disparó la inmediata respuesta del regulador norteamericano del mercado de valores –la Securities and Exchange Commission o SEC– quien notificó el inicio de investigaciones y la posibilidad de una inminente sanción.
La SEC señalaba que la información publicada podría haber afectado la cotización de los valores de Netflix y que, por lo tanto, debió sujetarse a los mecanismos de revelación establecidos. Netflix se defendió diciendo que la información no era material o relevante para el mercado por lo que no habría causado daño a los inversionistas.
Luego de todo este tiempo de investigaciones la SEC ha determinado que las redes sociales son mecanismos aceptables para comunicar información relevante para la empresa ampliando, de este modo, su opinión original en el sentido que solamente las páginas web corporativas cumplían con esta cualidad. No obstante ello, la SEC se ha cuidado de señalar que para que la comunicación de información a través de redes sociales sea aceptable y efectiva es preciso que los inversionistas hayan sido informados previamente de la futura utilización de estos medios para dar a conocer información relevante de la empresa. Si ello se cumple estaremos frente a un «fair disclosure» o una divulgación aceptable.
El mundo de las comunicaciones está cambiando y el mercado de valores recoge estos cambios para beneficio de un mejor y más rápido flujo de información. Sin embargo, persiste la duda de si estos nuevos «medios de comunicación» garantizan que la información llegue a todos los inversionistas de una manera que no beneficie a algunos en perjuicio de otros.
En principio, pareciera que la obligación de informar la utilización de estos nuevos medios protegería a todos los inversores al permitirles tomar las medidas necesarias para mantenerse al día con la información relevante de la empresa. No obstante ello, algunas preguntas quedan en el aire ¿Qué pasará con aquellos inversionistas que no usan twitter o facebook? ¿Se encontrarán en desventaja respecto de aquellos que sí? ¿Sería bueno que se obligue a los emisores a utilizar otros medios que garanticen una mejor distribución de la información?
Estaremos atentos a la evolución de esta normativa. Mientras tanto, les dejo el texto del Release No. 69279 de la SEC que regula esta materia (aquí).
Entrada publicada originalmente en el blog Cyberlaw del diario Gestión (aquí).

De Facebook y Anencefalia

El día de hoy leo con sorpresa del caso de Heather y Patrick Walker quienes en febrero sufrieron la pérdida de su hijo a tan sólo 8 horas de nacido. El bebé llamado Grayson James Walker nació el 15 de febrero con anencefalia, una patología congénita caracterizada por la ausencia parcial o total del cerebro, cráneo, y cuero cabelludo que no le permitiría vivir.
Sus padres, sabedores de esta noticia desde la decimosexta semana de gestación, contrataron un fotógrafo profesional para que recogiera la corta vida del bebé y del poco tiempo que sus padres pudieron disfrutar de su presencia (ver aquí). Posteriormente, procedieron a publicar estas fotos en su cuenta de Facebook. Grande fue su sorpresa cuando, poco tiempo después, esta red social eliminó las fotos de su perfil llegando, luego de que la madre iniciara una campaña con sus amigos para la re-publicación de las fotos, a eliminar el propio perfil de la madre (ver aquí).
Facebook sustentó estas sanciones en una supuesta violación de sus normas comunitarias. Estas normas o reglas de convivencia establecen nueve categorías de actividades que pueden dar lugar a una sanción por parte de Facebook, a saber: violencia y amenazas, conductas autodestructivas, acoso, lenguaje que incita al odio, violencia gráfica, desnudos y pornografía, propiedad intelectual, phishing y spam.
La indignada madre reclama en este video la sanción recibida y cuestiona que existan fotos con contenido violento o erótico que no son retiradas por Facebook.
Frente a esta situación nos surgen varias dudas: ¿Qué derecho tiene Facebook para retirar las fotos? ¿Es necesario que haya una denuncia previa? ¿Quién determina si un contenido finalmente viola o no las normas comunitarias? ¿Por qué existen publicados contenidos que violan las normas comunitarias de Facebook? ¿Está Facebook obligado a retirar todo el contenido violatorio existente? Veamos.
Dentro de las Condiciones de Uso de Facebook encontramos estipulaciones que nos indican que como usuarios nos obligamos a no publicar contenido que incite al odio, sea amenazante, pornográfico, que incite a la violencia o contenga desnudos o, lo que ellos denominan “violencia gratuita o gráfica”. Del mismo modo, se establece que Facebook puede retirar cualquier contenido o información si ”cree” que viola las referidas condiciones de uso. No obstante ello, establecen que ellos hacen su mayor esfuerzo para mantener segura su red social pero que “no pueden garantizarlo”.
Existe además una disposición interesante mediante la cual Facebook se reserva el derecho a suspendernos sus servicios en caso que violemos la letra o “el espiritu” de las Condiciones de Uso o si, de cualquier modo, creamos algún riesgo o posibilidad de exposición legal para ellos. Respecto de la anulación de nuestras cuentas son muy claros cuando nos dicen que pueden borrarla o suspenderla en cualquier momento sin hacer referencia a incumplimiento alguno.
Entonces, podemos concluir que, conforme a las Condiciones de Uso antes mencionadas, Facebook tendría el derecho de eliminar cualquier contenido que publiquemos sustentándose en términos tan ambiguos como el de “violencia gráfica o gratuita”; su “creencia” de que violamos sus condiciones o si violamos el “espíritu” de sus condiciones. Al tratarse de un servicio gratuito, podríamos pensar que Facebook tiene pues todo el derecho de hacer y deshacer dentro de sus dominios sin posibilidad alguna de reclamo por parte de los usuarios.
Como podemos ver no es necesaria la existencia de una denuncia previa pues Facebook tiene absoluta discrecionalidad para sancionar contenidos infractores. Pero podemos ir más allá pues, en sus normas comunitarias, Facebook deja claro que la existencia de una denuncia no garantiza que se vaya a producir el retiro del contenido que el denunciante objeta. Facebook sustenta su discrecionalidad en el hecho de que se trata de una red de alcance mundial y, como tal, contenidos que en algún lugar pueden considerarse ofensivos o violatorios de sus condiciones pueden no serlo en otro lugar. Por ello cierran sus normas comunitarias señalando que caad usuario es libre de escoger que contenidos va a ver y que si algo no nos gusta podemos ocultar a las personas, páginas o aplicaciones que consideramos ofensivas o, en un extremo, desconectarnos de los amigos que publicaron contenido que nos pudiera ofender.
Del mismo modo, Facebook tampoco está obligado a monitorear permanentemente toda su comunidad con el objeto de encontrar o detectar contenido violatorio pues ellos solo harán sus mejores esfuerzos para mantener su red social pero para eso, según dicen las condiciones de uso, necesitan nuestra ayuda. Por ello, el contenido reclamado por la madre estará ahí en tanto Facebook no lo encuentre, mientras alguien no lo denuncie y mientras Facebook no considere que violan sus términos de servicio.
Volviendo al caso de la familia Walker, estimamos que —al ser la anencefalia una enfermedad que produce deformaciones como consecuencia de la inexistencia de cerebro o cráneo y al haberse publicado fotos del bebé sin gorro o algo que le cubriera la cabeza—pueden haber existido personas que se sintieran afectadas. Aparentemente, este sentimiento fue recogido por Facebook para, amparándose en todas las reglas antes descritas, eliminar las fotos y suspender el perfil de la madre.
Al final, me quedan dando vueltas en la cabeza algunas preguntas que las dejo para futuros artículos ¿Es realmente Facebook un servicio gratuito? ¿Es que acaso no les pago con datos personales que luego monetizan? ¿No deberíamos tener mayores derechos al no ser tan gratuito como pensamos? Si finalmente fuera gratuito, ¿existe sustento para que mis derechos de usuario sean menores a los que tendría en caso fuera un servicio pagado?
Luego de SOPA y PIPA ¿qué viene o debería venir?
Esta semana el mundo gritó a voz en cuello NO A LA SOPA y NO A LA PIPA, proyectos de ley en el Congreso de Estados Unidos que buscan combatir la denominada piratería digital poniéndo en riesgo principios democráticos básicos como la libertad de expresión y el debido proceso. Más allá de la crítica, nos preguntamos ¿qué propuestas planteamos quienes nos oponemos radicalmente a ambas normas? he oído poco pero a eso debemos abocarnos. En la actualidad debe sin duda existir un mecanismo que permita tutelar los derechos de aquellos que no están de acuerdo con la difusión no autorizada de sus obras en la red así como equilibrarlos frente al acceso y la no censura de contenidos. Ello, en concordancia con los principios básicos de protección del derecho de autor que han sido adoptados por la mayoría de países del mundo a través de tratados internacionales como el Convenio de Berna y de otros convenios de derechos fundamentales.
El estándar anterior de SOPA y PIPA ha sido la Digital Millenium Copyright Act (DMCA). La sección de la DMCA que regula la responsabilidad de los proveedores de servicios de Internet (ISP) es 100% «Made in USA» ya que nunca estuvo contemplada como parte de los Tratados Internet de la Organización Mundial de Propiedad Intelectual (OMPI) y ha sido incluida en la mayoría de acuerdos de libre comercio que Estados Unidos ha celebrado con diversos Estados como Perú, Chile, Singapur, Australia, entre otras (en el Perú aún no la hemos implementado en legislación concreta y el plazo para hacerlo ha vencido largamente). La DMCA establece, entre otras disposiciones, un sistema de notificación y contra-notificación de acuerdo al cual si un titular detecta que alguien viene difundiendo alguna obra o creación suya sin su permiso notifica al intermediario para que lo retire, si éste no lo hace incurre en responsabilidad. Pongamos el ejemplo de Youtube.
El día 1 visualizamos un video de The Killers en Youtube. El día 2 enviamos el link del video a nuestros amigos. El día 3 preguntamos a nuestros amigos si vieron el video y uno de ellos nos dice «no, no pude entrar a verlo porque decía que había sido retirado por infringir derechos de autor». ¿Qué hace que Youtube retire ese video? Una obligación legal denominada DMCA. De hecho el conocido videoblogger peruano Luis Carlos Burneo utilizó los mecanismos ofrecido por la DMCA para denunciar una página que reproducía ilícitamente sus videos beneficiandose de la publicidad colocada en su site.
La DMCA no ha estado libre de críticas y una de ellas es que se convierte a los prestadores de servicios de Internet en censores y jueces de la red (crítica que se repite en SOPA y PIPA) generando incentivos para el retiro de contenidos considerados infractores a fin de evitar incurrir en responsabilidad. Es por ello que gobiernos como el chileno al momento de implementar las disposiciones de la DMCA contenidas en el acuerdo de libre comercio con Estados Unidos (concretamente la Ley de Propiedad Intelectual del 2010) han judicializado todo el proceso antes descrito en el ejemplo de Youtube antes mencionado. De esta manera que sea un juez y no el ISP quien tome la decisión final sobre la ilegalidad o no del contenido reclamado dando mayor garantía al procedimiento. Pese a las críticas la DMCA ha demostrado ser una herramienta que ha venido funcionando relativamente bien en la identificación de contenidos que infringen los derechos de autor. Es sin duda una norma perfectible.
En ese contexto de debate y polémica entre SOPAs y PIPAs, los senadores Wyden (Partido Demócrata) e Issa (Partido Republicano) han propuesto una alternativa a ambas, la Online Protection and Enforcement of Digital Trade Act (OPEN Act). OPEN propone que la United States International Trade Commission (ITC), agencia federal que brinda apoyo a los poderes Ejecutivo y Legislativo en materia de comercio internacional, el impacto del contrabando y otras prácticas desleales (y no el Departamento de Justicia) sea quien conduzca las investigaciones necesarias caso por caso. Quienes proponen OPEN argumentan que la lucha contra la piratería digital debe ser conducida por un equipo especializado y con experiencia en la materia. La iniciativa es apoyada por empresas como Facebook y Google, críticos intensos de SOPA y PIPA. Sin embargo la industria tradicional de contenidos no parece encontrar en OPEN la solución a sus problemas (ver el siguiente cuadro preparado por la Asociación de Bibliotecas Americanas que compara los tres proyectos de ley)
Lo anterior nos lleva a la pregunta que titula esta nota y es ¿qué viene o debería venir después de SOPA y PIPA?
- Creo que se viene una etapa de intensa e histórica discusión sobre los alcances de la regulación de Internet (libertad de expresión, derechos de propiedad intelectual, privacidad, etc). Más allá de etiquetas apocalípticas y fatalistas aludiendo a ciberguerras creo que puede ser una etapa de maduración y evolución de la regulación de Internet. Que un tema como SOPA y PIPA haya generado una protesta virtual global y cubierto las primeras planas de la prensa mundial no es poca cosa.
- En el plano legislativo OPEN Act es, en buena cuenta, recurrir al sistema de justicia tradicional a través de una entidad administrativa especializada (salvando las diferencias, un equivalente a nuestro INDECOPI). La profileración de iniciativas legislativas nacionales, plurilaterales y multilaterales con respecto al tema van seguir apareciendo.
- Es necesario revisar lo que se ha regulado a la fecha y trabajar sobre ello, la producción industrial de legislación diversa es ineficiente y costosa. Por lo pronto me parece importante revisar los alcances de la sección de responsabilidad de ISP en la DMCA y en nuestros acuerdos de libre comercio con Estados Unidos. Revisar dicha norma debe ser el punto de partida para iniciativas posteriores.
- Los titulares de derechos de autor van a seguir recurriendo a tribunales administrativos o judiciales para defender sus derechos (los casos Cuevana y Megaupload son un claro ejemplo de ello), lo cual al menos resulta más sano que aplicar legislación general como SOPA y PIPA que pueda minar derechos fundamentales como la libertad de expresión y alterar el funcionamiento y dinámica de la red.
- Fuera del plano legislativo o judicial, en el terreno privado seguirán ocurriendo situaciones como las de Eircom, el ISP más importante Irlanda, que en marzo de 2008 que fuera denunciado por la industria fonográfica irlandesa representada por la Irish Recording Music Association (IRMA). IRMA requería a Eircom filtrar material protegido por derechos de autor dentro de toda su red de usuarios. En febrero de 2009 ambas llegaron a un acuerdo extrajudicial según el cual Eircom filtraría contenidos bajo un sistema de tres strikes (a la tercera infracción desconectarían al usuario) (ver la nota de prensa sobre el acuerdo acá)
- Finalmente decir que no apoyar SOPA o PIPA no implica estar a favor de la piratería y el uso no autorizado de obras protegidas por propiedad intelectual. Quienes se oponen a SOPA como una justificación para seguir consumiendo productos libres de retribución, en mi opinión, están en un error. Quienes apoyan SOPA cómo una herramienta de protección de un negocio obsoleto también. El tema es uno de fondo y es como encontrar el equilibrio entre acceso y compensación.
Nos mantendremos atentos al creciente debate sobre el futuro de la regulación de Internet
La privacidad después de Facebook, en Gaceta Constitucional

El número 40 de la revista Gaceta Constitucional, publicación de Gaceta Jurídica, incluye un artículo mío titulado “La privacidad después de Facebook” (.pdf). El artículo describe la problemática existente entre el uso de servicios de redes sociales a través de Internet y el derecho fundamental a la privacidad. En particular, analizo la forma en que los límites de lo público y lo privado han sido redibujados por el influjo de servicios de redes sociales como Facebook y los posibles escenarios de vulneración del derecho a la privacidad en estos entornos.
Agradezco al equipo editorial de Gaceta Constitucional por haber tenido la gentileza de volverme a invitar a participar en su revista. Pueden visitar su página web para enterarse de dónde y cómo pueden adquirirla.
Paper.li o cómo crear tu propio diario
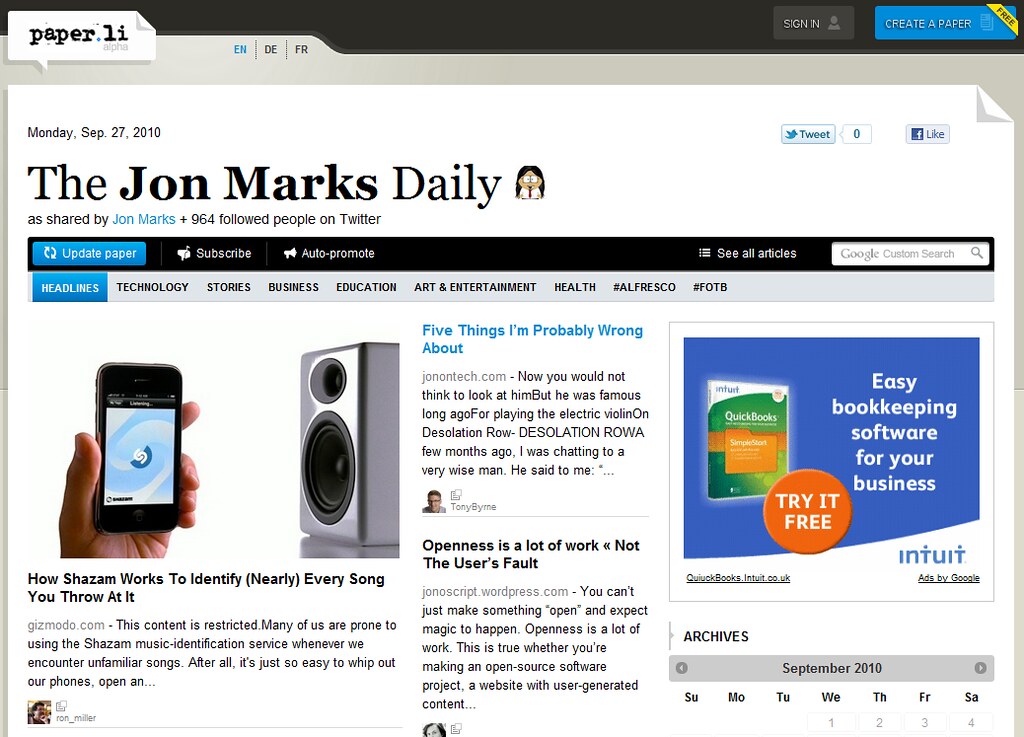
Hace unas semanas, preguntaba a nuestro cobloguero @watsamara si sabía de alguna herramienta que permitiera crear una especie de periódico digital a partir de enlaces alimentados por el propio usuario. Buscamos algunas alternativas, pero ninguna me satisfizo. Pensé en ese momento -parafraseando a Balzac-, que si no existía, había que inventarlo.
Pero Watsamara no se rinde con facilidad y hace unos días me comentó de paper.li, una herramienta que se apoya en los mensajes con links de quienes seguimos en Twitter o Facebook (en realidad la información más valiosa) para crear una especie de diario como el que andaba buscando.
Como es sabido, muchos usuarios de Twitter confían más en el criterio de selección de su red social para identificar enlaces a noticias importantes que en las compilaciones que realizan los diarios tradicionales. Paper.li recoge los enlaces a noticias, fotos y vídeos de una cuenta en Twitter; realiza una selección de estos vínculos a partir de un análisis que llama «herramientas de análisis semántico de texto» (semantic text analysis tools) -supongo que algo así como el algoritmo de Google o la fórmula de la Coca Cola- y, crea una página diaria editada a modo de los periódicos que vemos en Internet donde enlaces y contenido aparecen divididos en secciones contextuales.
¿Por qué hemos creado Paper.li? Se preguntan los creadores en su blog, la respuesta no es tan obvia: «no es por la sobrecarga de información es por la ausencia de un filtro«.
Si bien paper.li no es exactamente lo que venía buscando -no existe una real capacidad de autoedición-, me pareció una herramienta ingeniosa para dar un repaso a los enlaces más importantes que recibimos durante el día a través de Twitter o Facebook. La crónica de paper.li de Arturo Goga (aquí).
Paper.li es una creación de la startup suiza SmallRivers con sede en Lausanne y que opera desde el campus de la Escuela Politécnica Federal (École Polytechnique Fédérale De Lausanne, EPFL). No deja de valer para la anécdota que SmallRivers haya sido financiada en parte por la empresa de capital de riesgo Kima Ventures, uno de cuyos fundadores, Xavier Niel, adquirió recientemente el legendario diario francés Le Monde (Bussines Insider).
No es la única herramienta de esta naturaleza. The Tweeted Times (TT) permite crear un periódico virtual basado en el timeline de medios de prensa de una cuenta en Twitter o a partir de listas sugeridas por la propia aplicación. El inconveniente es que no se organiza en secciones basadas en temas, sino que constituye una larga cadena con los enlaces identificados por quienes seguimos en Twitter. No obstante, la ventaja de TT está en su regularidad, mientras que Paper.li se actualiza una vez al día, TT lo hace cada hora. Es probable que con el tiempo sigan apareciendo soluciones similares.
A estas alturas del debate sobre la supervivencia de la prensa o de su posible mutación en algo que todavía no sabemos qué será, es difícil saber si servicios del tipo Paper.li tendrán algún espacio en este ecosistema del futuro, sin embargo, no cabe duda que por el momento llenan un espacio en la dura tarea de organizar parte del frondoso bosque de información que vomitan (no se me ocurrió palabra más oportuna) diariamente las redes sociales. Incluso no sería descabellado que en un futuro los propios editores tradicionales integren estas herramienta dentro de los servicios provistos por el diario.
He empezado a utilizar Paper.li con regularidad y me parece que es una gran manera de ponernos al día sobre lo que se enlaza en Twitter. Sobre todo para quienes no estamos permanentemente conectados.
En realidad soy consciente que este tipo de servicios o como el Google News no nos entregan las noticias sino su eco, una reproducción de los contenidos más frecuentes, los más consultados, los más recomendados. La selección de esta selección siempre dejada a la sabiduría mecánica de un algoritmo. Luego vendrán los editores de los diarios, verdaderos sacrificados de la cultura del best off, a exigir un lugar dentro de este gran reparto informativo, ya que al fin y al cabo es a donde van a parar la mayoría de las rutas que seleccionan los algoritmos. Si los editores criticaron con dureza el Google News que es poco más que una colección de enlaces con su algoritmo, imagino lo que dirán si herramientas del tipo paper.li que descontectualizan totalmente el origen de la información se popularizan. Pero esta es otra historia.
Regulación sobre datos personales y publicidad basada en identidad

Hace poco hablaba sobre el manejo de datos personales por parte de los proveedores de servicios en un mercado online cada vez más basado en la identidad y no en la privacidad de sus usuarios. Así, conforme crece la demanda de contenidos en Internet y sus aplicaciones se hacen más sofisticadas, surgen modelos de negocio cuyo ingreso se sustenta en ofrecer publicidad dirigida a grupos de consumidores específicos seleccionados utilizando la información que poseen de ellos como edad, gustos, ciudad.
En un artículo reciente, Online Advertising, Identity and Privacy, Randal Picker ensaya la teoría de que cuando la regulación establece que ciertos agentes pueden usar la información libremente y otros están sujetos a una serie de obligaciones legales para hacerlo, modificamos sustancialmente el equilibrio competitivo de un mercado. Sin embargo, precisa, eso no significa que debamos construir nuestra regulación desprotegiendo por completo a los usuarios. Por el contrario, propone diseñar un marco legal que propicie el equilibrio entre el uso de información personal con fines comerciales y el derecho de los usuarios.
En este escenario, según Picker, importa mucho dónde se coloque la regulación sobre privacidad frente a la publicidad basada en identidad y en comportamiento del usuario, al ser un mecanismo de financiamiento privilegiado. El modelo de regulación clásico, pensado para casos como el envío de publicidad no deseada, impide a las empresas utilizar la información de sus usuarios sin su consentimiento previo. Pero nuevos usos de esa información, como mostrar publicidad basada en identidad, nos hacen replantearnos este modelo si tenemos en cuenta que financia la mayoría de contenido gratuito y, cuando no lo hace, puede ser útil ver publicidad basada en su perfil (ej. las recomendaciones de compra Amazon). La pregunta es si dicho permiso debe ser un ajuste por defecto y con opción a restringirlo por parte del usuario del servicio (sistema opt-out) o un ajuste que el usuario podría implementar manualmente si lo desea (sistema opt-in).
Dos respuestas distintas
En Estados Unidos, la Federal Trade Comission ha emitido cuatro principios de autorregulación para la publicidad basada en identidad y comportamiento (como la de Facebook o la de Google, si usa mi historial de búsquedas anteriores) invocando a las empresas a transparentar sus prácticas al respecto, obtener autorización expresa siempre que se trate de datos sensibles (salud, finanzas) o cambie sus políticas y tomar las medidas de seguridad razonables para proteger los datos. Sobre la pregunta del ajuste por defecto, ha optado porque los servicios puedan usar sistemas opt-in u opt-out y que sean los usuarios quienes modifiquen sus preferencias de consumo según el sistema con el cual se sientan más cómodos. Se ha excluído expresamente de estos principios los supuestos de publicidad de la propia empresa y la publicidad contextual (AdWords) porque considera que, en estos casos, no hay potenciales brechas de privacidad.
De cómo nuestros datos personales salvarán la industria de contenidos

Hay algo que me llama la atención en la ficción sobre sociedades futuristas. Quizás inspiradas en la producción industrial en serie, muchas distopías previas a la masificación de Internet presentaban la sociedad del futuro con un gran tendencia a la homogenización, donde cada persona había perdido su identidad y era clasificada en grupos. (ej. El Proceso, Brave New World, 1984). Mucha de la ficción post Internet, en cambio, propone una sociedad en donde el mercado tiende a diversificar y personalizar su oferta al punto que los seres humanos han perdido toda exposición a cosas que no sean de su interés como abrir un diario o ver la televisión sin saber qué programa va a dar (ej. Minority Report, Wall-E, Idiocracy).
La principal diferencia entre ambos modelos de sociedad es la existencia de productos y servicios inteligentes: capaces de modificarse según cada usuario. Pensemos en la escena de Minority Report en donde el protagonista es recibido en una tienda de GAP por un holograma que lo llama por su nombre y le pregunta cómo le fue con su última compra. Nada muy lejano a la forma en la que Google o Youtube muestran anuncios en base a nuestro historial de búsqueda o Facebook coloca la publicidad de acuerdo con nuestros intereses, ciudad o grupo de amigos.
Los datos personales como forma de financiamiento
Otra cosa en común que tienen Google y Facebook es que son gratuitos. No nos cobran por usar el correo, ni por almacenar nuestras fotos, ni por ver videos en Youtube. Su única fuente de ingresos es la publicidad. Para cualquier anunciante, la inversión en publicidad está directamente relacionada con la posibilidad de que sea vista por su público objetivo, los clics hechos y la rentabilidad que ello le pueda generar. Si los medios en los que anuncian son capaces de asegurar que el público objetivo del anunciante verá su publicidad, el anunciante estará dispuesto a pagar más y los medios (Google o Facebook) podrán mejorar sus servicios y se asegurarán de colocar publicidad poco intrusiva. Tener acceso a la información personal de sus usuarios, por ende, no solo beneficia su negocio sino que también beneficia a sus usuarios, quienes siguen disfrutando de los servicios en forma gratuita.
Pero esto no es nada nuevo. Quien anuncia a en un concierto de Grupo 5 quiere llegar a un público distinto del que anuncia en uno de La Mente. Comprar un determinado producto o servicio revela mucha información sobre nosotros y eso le permite a un anunciante mejorar la eficacia de su publicidad. Durante los primeros años de Internet, esto era complicado porque un sitio web sabía relativamente poco sobre sus visitantes. El no saber quién y dónde verá la publicidad fue siempre una traba para el financiamiento de los servicios en línea. La materialización del sueño de una red de usuarios con nombre propio como la de Facebook, por el contrario, está permitiendo que servicios de calidad como Gmail o Twitter sean gratuitos.
De hecho, esta podría ser la solución al gran problema del financiamiento de las industrias de contenidos en Internet. Pensemos en Spotify, una aplicación que permite acceder a una biblioteca de más de ocho millones de canciones sin necesidad de descargarlas y en óptima calidad. Existe un servicio gratuito y uno de pago. El gratuito está financiado por publicidad, que se muestra en la pantalla como un banner y se escucha por veinte segundos cada cierto número de canciones. Nuevamente, la información que recolecta la empresa sobre nuestra localización geográfica, hábitos de escucha y su reciente integración con Facebook le permite subir el costo de sus anuncios y financiar su servicio retribuyendo a las discográficas y artistas. Cada vez un número mayor de servicios empiezan a ver este modelo como viable (Grooveshark, Hulu).
En un reciente artículo, Online Advertising, Identity and Privacy, Randal Picker ensaya la tesis de que cuando la regulación establece que ciertos agentes pueden usar la información libremente y otros están sujetos a una serie de obligaciones legales, modificamos sustancialmente el equilibrio competitivo de un mercado. A los argumentos de Picker y a lo que nuestro propio proceso legislativo de protección de datos personales puede aprender de este nuevo escenario dedicaré mi siguiente entrada.
Foto: Chloe Lorena ©